Advancing Real-World Super Resolution Images Using a Semantic-aware Restoration Approach
Other Articles

A novel two-stage, degradation-aware framework enhances the diffusion model’s ability to recognise content and degradation in low-resolution images. It regenerates realistic image details while preserving semantics, demonstrating state-of-the-art performance across various benchmarks.
Study conducted by Prof. Lei ZHANG and his research team
and his research team
Digital data transmission could lead to image degradation, resulting in output images that have low-resolution, are blurry and/or noisy. With powerful generative capabilities, pre-trained large scale diffusion models play a crucial role in addressing real-world super-resolution (SR) challenges in recent years. This approach leverages the principles of diffusion processes (originating from thermodynamic theory and describing how particles spread over time) and gradually transforms the noise into high-resolution (HR) images under the control of the given low-resolution (LR) input1. The models are composed of the diffusion process and reverse process, where the diffusion process progressively increases the noise in the HR image content, and the reverse process reconstructs the HR image from noise by score estimating. Specifically, text-to-image (T2I) diffusion-based real-world image SR methods aim to improve inverse image restoration by using text prompts to produce coherent output images with higher resolution. However, existing models still encounter several limitations. For example, some methods rely solely on given LR input images as control signals, overlooking the important role of semantic text information in the pretrained T2I models. Other methods encounter difficulties when dealing with scenes containing a variety of objects or severely degraded images, and problematic noise handling that erase details in the scene. It remains a question of how to extract more effective semantic prompts to harness their generative potential to obtain better Real-ISR results.
A research team led by Lei ZHANG, Chair Professor of Computer Vision and Image Analysis in the Department of Computing at the Hong Kong Polytechnic University, a pioneer in developing deep convolutional neural networks (CNN) for image denoising2, proposes a Semantic-aware SR (SeeSR) approach, which utilises high-quality semantic prompts to enhance the generative capacity of pretrained T2I models for Real-ISR3. The training of SeeSR occurs in two stages:
(a) Degradation-Aware Prompt Extractor (DAPE): This is the first stage of the training process. In this stage, the HR image is randomly degraded into an LR image. This process involves two image encoders—one for the HR image and another for the LR image. Both encoders output representation embeddings through corresponding tag heads, which are used for initialisation and trained using representational loss and logits loss (Fig. 1(a)). The goal of DAPE is to recognise the relationship between the degraded image and the original HR image, extracting high quality tag-style prompts that contain category information for all objects in the image. These prompts aid in the subsequent restoration process.
(b) Real-ISR with DAPE: The trained DAPE is used in the second stage for real image super-resolution (Real-ISR). DAPE provides both soft prompts (representational embeddings) and hard prompts (image tags), which, when combined with the LR image, control a pre-trained T2I diffusion model (Fig. 1(b)). The purpose of this model is to restore the LR image to be as close as possible to the original HR image.
(c) Controlled T2I Diffusion Model: This is the core of the system, featuring a detailed structure for processing image and text prompts. The model has three branches: an image branch, a text branch, and a representational branch. SeeSR uses a trainable control module to guide the generation process of a pre-trained UNet. Additionally, it extracts features from tag-style prompts via a text encoder and feeds them into a text cross-attention (TCA) module. The representation embedding from this step is then used to control the representation cross-attention (RCA) module (Fig. 1(c)). Once training is completed, the entire Controlled T2I diffusion model can perform the reverse process, progressively generating HR images from LR inputs. During the inference process, the research team integrates the LR images into the initial sampling noise to mitigate the diffusion model’s tendency to generate excessive random details.
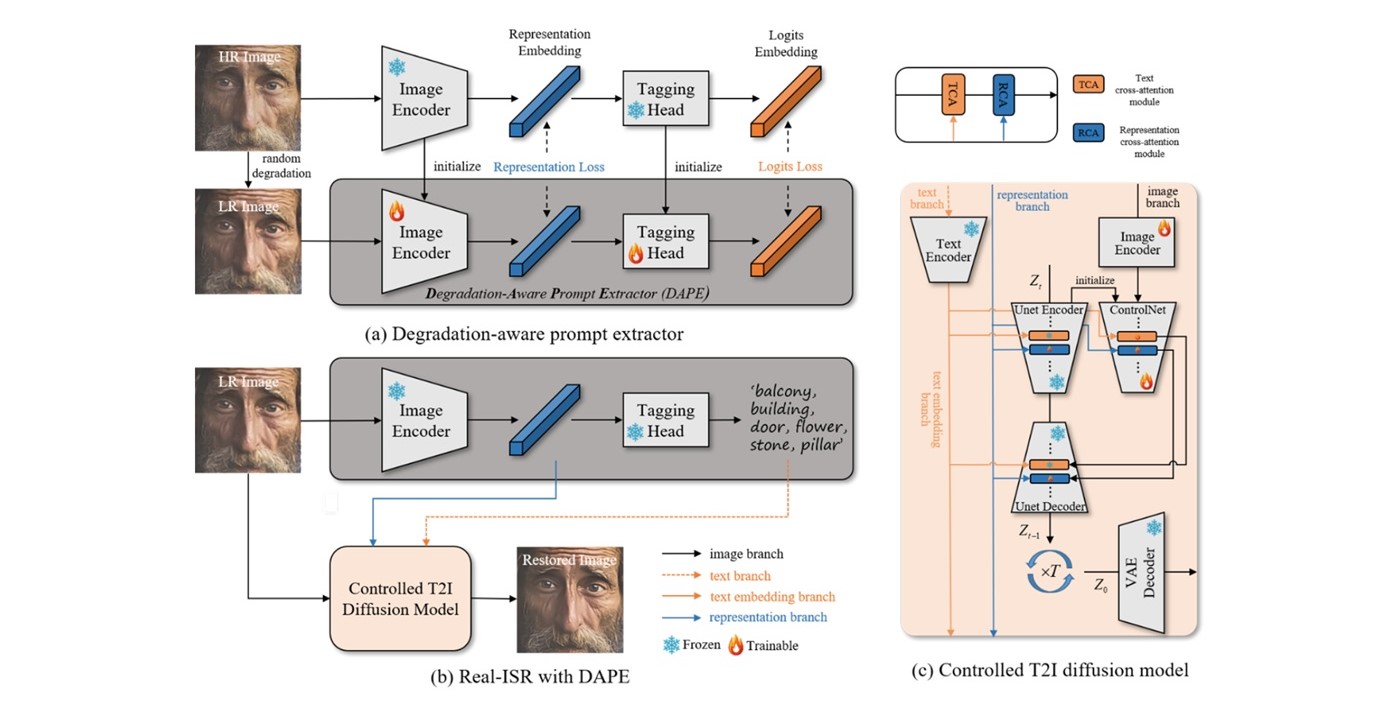
Figure 1. Overview of Semantic-aware Super Resolution (SeeSR) method.
The entire system aims to enhance the performance of image super-resolution, particularly when dealing with degraded images. By controlling the generation process through the combination of text and image prompts, it provides more accurate and detailed results. In this way, SeeSR can generate visually satisfying and detail-rich high-resolution images. After model training and testing, experiments suggest that the See-SR method outperforms other benchmarking methods when comparing the results of widely used evaluation metrics. When applied to synthetic and real-world images, the See-SR method reproduces more realistic image details and better preserves semantics among other methods, successfully reconstructing the details of an object without degradation and retaining rich details of the image with the aid of semantically-accurate prompt generated by the model (Fig. 2). With significant progress in leveraging generative priors to synthesize semantically correct and robust Real-ISR images, the research team has successfully developed a cutting-edge approach, which could lead to meaningful applications across the digital era.

Figure 2. Qualitative comparisons between the SeeSR method and other state-of-the-art Real-ISR methods.
LR: Low resolution;
GT: Ground truth image (Reference);
LDM: Latent diffusion models;
BSRGAN: A deep blind ESRGAN super-resolver;
StableSR: An approach that preserves pretrained diffusion priors without making explicit assumptions about the degradations;
Real-ESRGAN: Real World-Enhanced Super-Resolution Generative Adversarial Networks;
ResShift: A diffusion model tailored for super resolution;
LDL: A locally discriminative learning approach to realistic image super-resolution;
PASD: Pixel-aware stable diffusion;
DASR: Degradation-adaptive network for super-resolution;
DiffBIR: Blind image restoration with generative diffusion prior; FeMaSR: Real-world blind super-resolution via feature matching with implicit high-resolution priors;
SeeSR: Semantic-aware super-resolution approach.
The research is supported by the Research Impact Fund from the Research Grants Council of the Hong Kong Special Administrative Region, China (R5001-18) and the PolyU-OPPO Joint Innovation Lab. The source code of the study is available at https://github.com/cswry/SeeSR.
| References |
|---|
1. Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, 6840–6851 (2020).
https://proceedings.neurips.cc/paper_files/paper/2020/hash/4c5bcfec8584af0d967f1ab10179ca4b-Abstract.html
2. Zhang, K., Zuo, W., Chen, Y., Meng, D., and Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Transactions on Image Processing. 2017 July;26(7):3142-3155. doi: 10.1109/TIP.2017.2662206.
3. Wu, R., Yang, T., Sun, L., Zhang, Z., Li, S., & Zhang, L. SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution. Proceedings – IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, Washington, 17 – 21 June, 2024
https://doi.org/10.48550/arxiv.2311.16518
 | Prof. Lei ZHANG Chair Professor in the Department of Computing |


