Many a Little Makes a Mickle: A Distributed Approach Pioneering the Edge GenAI Revolution
Other Articles

An energy-saving approach to train and sample smaller models that evolve into comprehensive GenAI.
Study conducted by Prof. Hongxia YANG and her research team
and her research team
Generative Artificial Intelligence (GenAI), a class of AI systems designated to create new content by learning patterns from existing data (for example, OpenAI’s GPT), is rapidly gaining attention. It offers advanced tools like Large Language Models (LLM), Multimodal LLMs, and Stable Diffusion, with significant potential for growth. Edge GenAI refers to the deployment of GenAI models at the edge of a network, closer to the data source or end-user devices, instead of relying solely on centralised cloud computing. It represents the future of broad GenAI applicability across enterprises and applications, transforming AI through improved cost efficiency, energy conservation, privacy, and personalised experiences. However, the enormous computational costs in both data training and sampling form a bottleneck in the development of Edge GenAI.
Lauded by Forbes China as one of the Top 50 Women in Tech in 2022, Hongxia YANG, a Professor in the Department of Computing at the Hong Kong Polytechnic University, introduced a decentralised paradigm that targets edge-based GenAI for specialised reasoning and planning applications, aiming to surpass industry benchmarks established by leaders like OpenAI. Her research team has been focusing on three pivotal technologies essential for the success of Edge GenAI, including the Unified GenAI Distillation Paradigm, Low Resource Inference and Learning, as well as Multimodal Reasoning and Planning.
The research team introduced the Single-step Distillation (SiD)1, an innovative approach that transforms complex pretrained models into efficient generators. This approach enables the training of smaller models that can evolve into comprehensive GenAI, substantially lowering the costs of training and computation. In an experiment detailed below, the research team demonstrated that the method notably improves performance metrics by over 30% and reduces computational demands through score-matching loss minimisation, representing a significant advancement in GenAI distillation paradigms.
In addressing challenges in low-resource environments in generating low-realistic images, the research team unveiled the novel “Local-feature Enrichment and Global-content Orchestration” (LEGO) architecture at the Twelfth International Conference on Learning Representations (ICLR) in Vienna, Austria on 8th May, 20241. The novel architecture comprises a series of modular components, akin to “LEGO” bricks, that transform complex pretrained models into efficient generators. The modular components have different input sizes, designed to process local patches of various parts of an image. Suitable modular components are then stacked together to improve the overall quality of image and to assemble a diffusion model. The process involves two steps. Firstly, in the “Local-feature Enrichment”, the model analyses a specific section of the image and breaks it down into smaller pieces with a “token” embedding layer in different input sizes for local patching (Figure 1). Secondly, in the “Global-content Orchestration” process, the model reaggregates the local token-embedding features into an image with refined spatial information at a higher resolution. This approach is efficient since each modular component is trained in local regions using sampled input patches instead of the entire image in the neural network, and the flexible utilisation of each modular component enables image generation with a smaller network. Additionally, the stackable feature of modular components facilitates a unique reconfigurable architecture of the model, enabling it to generate images with higher resolution than the training data. Compared to conventional methods, this architecture significantly reduces graphics processing unit (GPU) load and cuts sampling times by 60%.
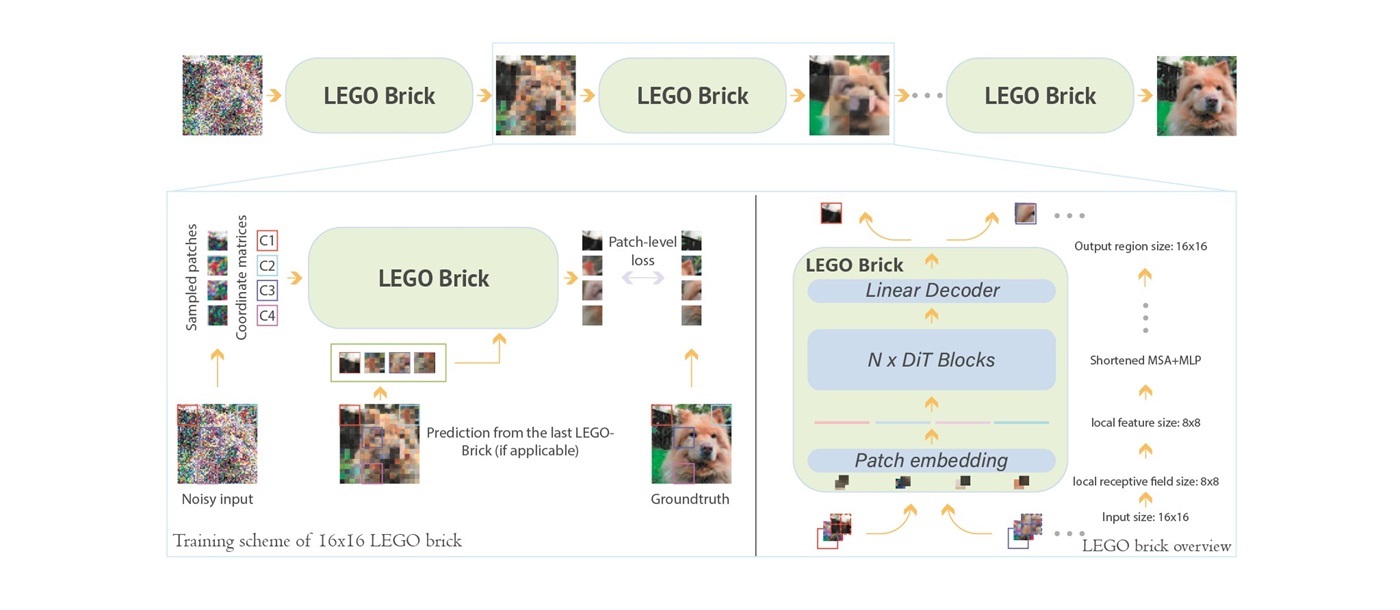
Figure 1. An overview of the training scheme of “Local-feature Enrichment and Global-content Orchestration” (LEGO) trick
As presented at the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) in Bangkok, Thailand, from 11 to 16, August, 2024, the research team offers new solutions for the development of efficient Multimodal Large Language Models (MLLM) that integrate diverse data types (e.g. text and images) for content creation and responses to enquiries. A cutting-edge approach, InfiMM is proposed2, which utilises smaller-scale models within the Flamingo architecture3 and incorporates autoregressive (AR) techniques to dynamically integrate information from different modalities (e.g. visual and text data) to generate sequential outputs (Figure 2). A three-stage procedure is employed to train the model: In the pretraining stage, the research team used a diverse set of mapped image-text pairs as well as unstructured multimodal web documents to train the alignment between the visual and language modalities at instance-level. In the next stage, other domains, such as scene-based and OCR-based datasets are included for multi-task training, enabling the model to respond flexibly in different contexts and to enhance its overall understanding capability. In the final stage, a set of 665k instruction tuning data that was previously used to train other MLLM models4 is applied to increase the model’s responsiveness to user instructions. By developing the “chat” function, this process allows the model to more accurately understand user needs and provide appropriate responses or actions.
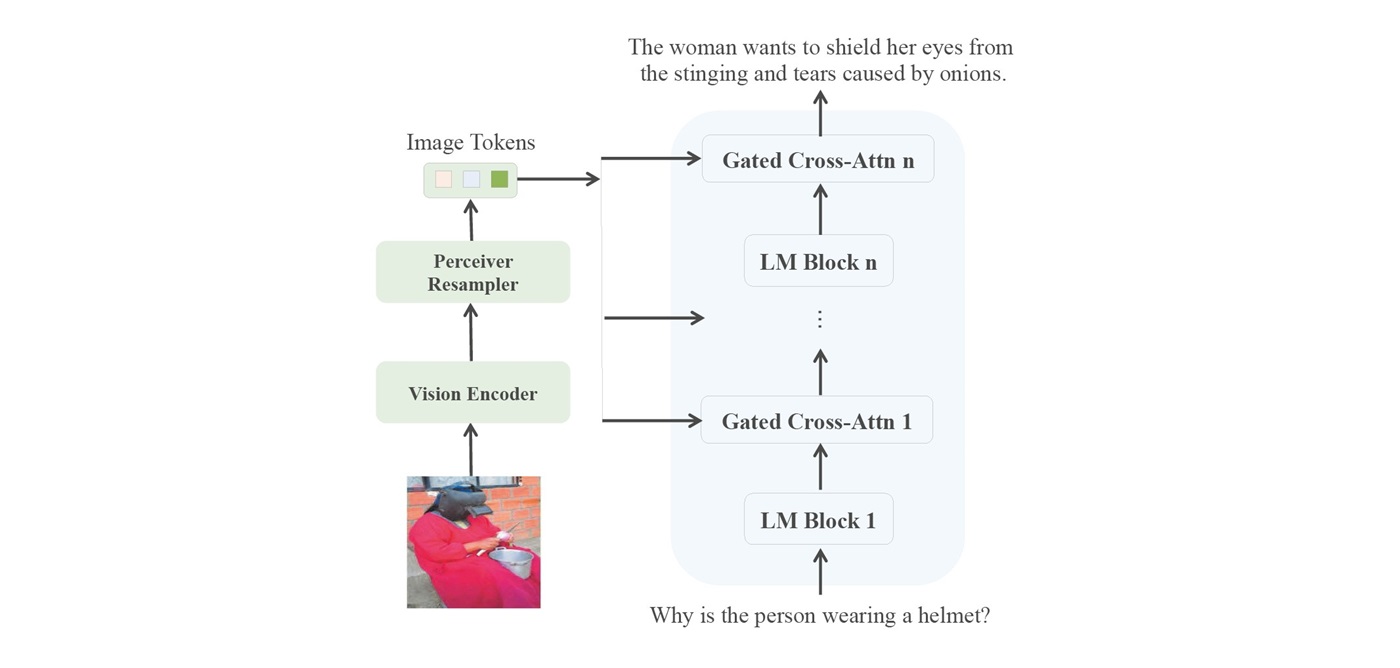
Figure 2. The overview architecture of InfiMM. InfiMM consists of a vision encoder, a Perceiver Resampler, and a large language model with a Gated Cross-attention module
The training methods of InfiMM emphasise not only the alignment of features and the injection of knowledge but also the model’s flexibility and adaptability in practical applications. Such design enables InfiMM to demonstrate excellent handling of complex visual and language tasks, and it holds significant application potential in the field of multimodal learning. The innovations and implementations of these methods provide valuable references for the future development of multimodal models.
The innovative approaches suggested by the research team have optimised Unified GenAI Distillation Paradigm, Low Resource Inference and Learning, as well as Multimodal Reasoning and Planning, making the models more favourable for deployment. In addition, the research team has also achieved competitive results for LLM reasoning in coding5 and agent6. By bringing them altogether, these advancements pave the way for the development of Edge GenAI, making it more accessible and effective for practical applications. We observed that Japan’s Sakana AI, a leader in the distributed LLM concept, swiftly achieved a valuation of $1.5 billion in just six months. Unlike their approach, which requires models to share the same pretrained backbone and size, we propose an unconstrained model merging framework7. This offers a more flexible foundation for decentralised LLMs, representing a significant advancement from the current centralised LLM framework. This evolution could encourage broader participation and stimulate further progress in artificial intelligence, effectively addressing the limitations of centralised models. We believe this innovative machine learning paradigm represents the future of GenAI.
The research on the development of single-step distillation model and the LEGO architecture is supported by the National Science Foundation (NSF-IIS 2212418), the National Institute of Health (NIH-R37 CA271186), and the AI Institute for Foundations of Machine Learning (IFML) of the National Science Foundation (NSF). The code and model of the studies are located at https://huggingface.co/Infi-MM and https://jegzheng.github.io/LEGODiffusion.
| References |
|---|
1. Zheng, H., Wang, Z., Yuan, J., Ning, G., He, P., You, Q., Yang, H., & Zhou, M. (2024, May 7). Learning Stackable and Skippable LEGO Bricks for Efficient, Reconfigurable, and Variable-Resolution Diffusion Modeling. The Twelfth International Conference on Learning Representations (ICLR), Vienna, Austria. https://doi.org/10.48550/arxiv.2310.06389
2. Liu, H., You, Q., Han, X., Wang, Y., Zhai, B., Liu, Y., Tao, Y., Huang, H., He, R., & Yang, H. (2024). InfiMM: Advancing multimodal understanding with an open-sourced visual language model. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), Bangkok, Thailand, 485 – 492. https://doi.org/10.48550/arXiv.2403.01487
3. Alayrac, J.-B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y.,… Simonyan, K. (2022). Flamingo: a Visual Language Model for Few-Shot Learning. Advances in Neural Information Processing Systems, 35:23716–23736. https://doi.org/10.48550/arxiv.2204.14198
4. Liu, H., Li, C., Li, Y., & Lee, Y. J. (2024). Improved Baselines with Visual Instruction Tuning. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, United States, 26296-26306. https://doi.org/10.48550/arxiv.2310.03744
5. Yu, Z., Tao, Y., Chen, L., Sun, T., & Yang, H. (2024, May 7). B-Coder: Value-Based Deep Reinforcement Learning for Program Synthesis. The Twelfth International Conference on Learning Representations (ICLR), Vienna, Austria. https://doi.org/10.48550/arxiv.2310.03173
6. Hu, X., Zhao, Z., Wei, S., Chai, Z., Ma, Q., Wang, G., … Yang, H., & Wu, F. (2024). InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks. Proceedings of Machine Learning Research, 235, 19544-19572. https://doi.org/10.48550/arxiv.2401.05507
7. Zhang, Y., He, B., Zhang, S., Fu, Y., Zhou, Q., Sang, Z.,... Yang, H. (2024) Unconstrained Model Merging for Enhanced LLM Reasoning. https://doi.org/10.48550/arxiv.2410.13699
| Prof. Hongxia Yang Professor in the Department of Computing |



